Balsa: Learning a Query Optimizer Without Expert Demonstrations (WIP)
- Authors: Zongheng Yang, Wei-Lin Chiang, Sifei Luan, Gautam Mittal, Michael Luo, Ion Stoica
- Institute: UC Berkeley
- Published at SIGMOD'22
- Paper Link: https://arxiv.org/abs/2201.01441
Background
Query optimizer is an important component that finds out a good execution plan for a query.
Motivation
DBMS without Good Optimizer
雖然像是 PostgreSQL 這些 DBMS 都有很成熟的 Query Optimizer,但是比較新興的系統像是近年的 NewSQL 系統就沒有成熟的 Query Optimizer。 然而為每一個系統設計一個成熟的 Query Optimizer 非常花費時間。
因此如果能用一個 ML Model 來替代的話會方便很多。
RL without Demonstration
之前已經有過許多用 RL 實作 Query Optimizer 的研究,然而這些做法都是假設有一個成熟的 Query Optimizer 存在,並提供過去的經驗做為學習對象。不過在缺乏這種 optimizer 的系統上,就無法直接引用這些做法解決問題。
因此需要一種不需要有專家 (成熟的 optimizer) 也能夠用的 RL 作法。
Problem
在沒有其他 expert optimizer 的情況下使用 RL 替代 query optimizer。
Challenges
- 沒有 expert optimizer,這點可能會造成毫無方向的 exploration,以及大量的 exploration 時間
- 如何避免找到很糟糕的 plan 導致大量的時間浪費
- 如何有效率的學習避免花費大量時間尋找好的 plan
Assumptions
- Database 資料不會改變
- 假定 query plan 會被拆成 select-project-join block 進行處理
Previous Work
- DQ: 學習 query optimizer 的 cost model,因此 performance 被 cost model 給限制住
- Neo: 先從 query optimizer 產生過的 plan 學習,然後在實際環境中執行
這些方法都假定有 expert cost model 或者 optimizer。
Method
這篇 paper 提出的作法就是 simulation-to-reality learning,也就是先在 simulated 的環境中學習,然後在轉移到實際環境中學習。這樣可以在 simulation 階段就避免花時間執行很差的 query plan。
他們提出一個重要的 insight:只要使用非常簡單的 simulator 就可以達到有效避免糟糕 plan 的效果,甚至在 simulation 之中的 label 也不用跟實際執行時相同。
Simulator
Balsa 建立了一個非常簡易的 simulator,input 是一個 query plan,output 是 cost,這邊 cost 是每一個 operator 的 output records 數量加總。其中每一個 operator 的 cost 依照下列公式計算:
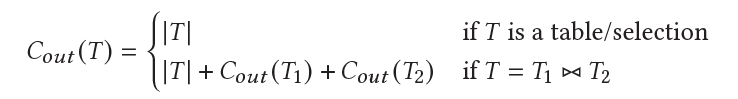
其中 |T| 需要依賴一個現有的 cardinality estimator 得到,這邊使用的 PostgreSQL 的 estimator。
這邊 paper 雖然沒有明講,但可以看出應該有以下假設:
- Join 假設用 hash join
- Join 的 selectivity 假設是 1
- 只 model join 跟 scan 的 cost
注意作者們發現就算這個 simulator 這麼簡單,光是利用這個 simulator 跑過就可以讓 agent 從找到慢 79 倍的 plan 變成最爛只會找到慢 5.8 倍的 plan。
接著 Balsa 使用 Selinger-style optimization 作法針對一組給定的 query 生成一連串的 query plan,並將這些 query plan 之中所有的 sub plan 與 cost 組合都記錄到 data set 之中。
最後 Balsa train 一個 neural network \(V_{sim}\): (query, sub-plan) -> (cost)
Real Execution
在實際的環境之中,Balsa 的目標是要 train 一個 neural network \(V_{real}\): (query, sub-plan) -> (overall latency)。
要特別注意兩點:
- \(V_{real}\) 與 \(V_{sim}\) 的 label 不同,採用的是實際的 latency 而不是 cost,但 \(V_{real}\) 會用 \(V_{sim}\) 的 weights 來初始化。
- \(V_{real}\) 的 overall latency 指的是「包含這個 sub-plan 之後執行整個 query 的 latency」,而且這邊會特別找在過去所有出現這個 sub-plan 的 query 之中最好的那個 latency。
實際上運行的時候採用以下方法來蒐集資料跟 training:
- 收到一個 query
- 利用 Balsa 提出的 plan search 作法搭配現在的 \(V_{real}\) 來找到最好的 k 個 query plans
- 從 k 個 query plans 之中挑出「沒看過的 query plan」執行,並記錄 latency。如果都看過的話挑預測最快的那個。
- 將執行的 query plan 與 sub-plan 搭配 overall latency 記錄下來放進 data set 中
- 使用 SGD 搭配 L2 Loss 更新 \(V_{real}\)
Plan Search
Plan search 的做法採用的是 NLP 之中常見的 beam search。
Beam search 會維護一個 priority queue,並且設定長度為 b。這邊 Balsa 會將建立一個 plan tree 之中每一個中間的 state 當作一個點,然後放進 queue 裡面跑 beam search。這邊描述執行步驟:
- 將 query 之中所有需要使用的 table 找出來,並組合出初始 state: {T1, T2, T3...}
- 將初始 state 放進 queue 中
- Beam search 會從 queue 中 pop 出一個 state
- 將所有可能可以對這組 state 執行的動作執行一遍,每一個動作都會產生新的 intermediate state。要執行的動作包含:
- 要 join 哪兩個 sub-plan/tables
- Join 的 operator 要選擇甚麼 (hash, merge...)
- 對每一個產生出來的 intermediate state 裡面包含的 sub-plan 使用 \(V_{real}\) 估計 overall latency,並取最差的當作整組 state 的 latency。
- 將所有產生出來的 state 塞進 queue,queue 會依照 latency 從小到大排序
- 回到第 3 步,直到產生出 k 個完整的 query plan。
Some Tricks
這篇論文有一些額外的發現,讓整個 training 的效果會更好:
- On-policy learning: 只使用最新的 \(V_{real}\) 產生的 data point 來更新 \(V_{real}\),他們發現這樣可以加速更新速度
- Timeout Policy: 如果有些 query plan 跑超過一個上限,就直接終止 execution 並給定一個上限時間
- Count-based exploration: 採用 beam search 出來的 top-k 個 plan 時,使用最沒看過的那個,而不是最快的那個。這樣可以增加 exploration 的 diversity。
- Diversified experiences: Balsa 會訓練 N 個 agent,並採用不同的 random seed,最後將這 N 個 agent 收集的 data set 合併來訓練一個新的 agent,這樣可以大幅增加 experience 的 diversity,提升 agent 的 generalizability。
Experiments
Conclusion
Questions
- 真的現有的 RL 做法都需要 expert demonstration 嗎?
- 從做法看起來,其實就是先從一個簡單的 cost estimator learn 一個 estimator model,然後再利用實際環境 fine tune 這個 model。而尋找 plan 的方法仍是使用現有的 algorithm 搭配 learn 好的 estimator model 學習。這樣真的有比較好?